¿Qué son los modelos de lenguaje?
Las aplicaciones de IA generativa se basan en modelos de lenguaje, que son un tipo especializado de modelo de Machine Learning que se puede usar para realizar tareas de procesamiento de lenguaje natural (NLP), entre las que se incluyen las siguientes:
- Determinar opiniones o clasificar de otro modo un texto de lenguaje natural.
- Resumir un texto.
- Comparar varios orígenes de texto en busca de similitud semántica.
- Generar nuevo lenguaje natural.
Aunque los principios matemáticos subyacentes a estos modelos de lenguaje pueden ser complejos, comprender los aspectos básicos de la arquitectura que se usa para implementarlos puede ayudarle a entender conceptualmente cómo funcionan.
Modelos de transformador
Los modelos de aprendizaje automático para el procesamiento de lenguaje natural han evolucionado a lo largo de muchos años. En la actualidad, los modelos de lenguaje grande más recientes se basan en la arquitectura del transformador, que aprovecha y amplía algunas técnicas que han demostrado su eficacia en el modelado de vocabularios para respaldar tareas de PLN y, en particular, en la generación de lenguaje. Los modelos de transformador se entrenan con grandes volúmenes de texto, lo que les permite representar las relaciones semánticas entre palabras y usar esas relaciones para determinar secuencias probables de texto que tienen sentido. Los modelos de transformador con un vocabulario lo suficientemente grande son capaces de generar respuestas de lenguaje difíciles de distinguir de las respuestas humanas.
La arquitectura del modelo de transformador consta de dos componentes o bloques:
- Bloque codificador que crea representaciones semánticas del vocabulario de entrenamiento.
- Bloque descodificador que genera nuevas secuencias de lenguaje.
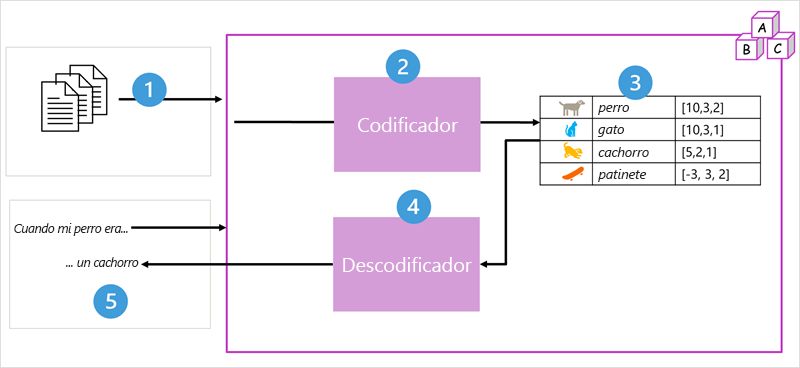
- El modelo se entrena con un gran volumen de texto de lenguaje natural, a menudo procedente de Internet u otros orígenes públicos de texto.
- Las secuencias de texto se dividen en tokens (por ejemplo, palabras individuales) y el bloque del codificador procesa estas secuencias de tokens mediante una técnica denominada atención para determinar las relaciones entre tokens (por ejemplo, qué tokens influyen en la presencia de otros tokens en una secuencia, tokens diferentes que se usan normalmente en el mismo contexto, etc.)
- La salida del codificador es una colección de vectores (matrices numéricas con varios valores) en la que cada elemento del vector representa un atributo semántico de los tokens. Estos vectores se conocen como inserciones.
- El bloque de descodificador funciona con una nueva secuencia de tokens de texto y usa las inserciones generadas por el codificador para generar una salida de lenguaje natural adecuada.
- Por ejemplo, dada una secuencia de entrada como "Cuando mi perro era", el modelo puede usar la técnica de atención para analizar los tokens de entrada y los atributos semánticos codificados en las incrustaciones para predecir una finalización adecuada de la frase, como "un cachorro".
En la práctica, las implementaciones específicas de la arquitectura varían, por ejemplo, el modelo de representación de codificador bidireccional de transformadores (BERT) desarrollado por Google para respaldar su motor de búsqueda solo usa el bloque codificador, mientras que el modelo de transformador generativo preentrenado (GPT) desarrollado por OpenAI solo usa el bloque descodificador.
Aunque una explicación completa de todos los aspectos de los modelos de transformador está fuera del ámbito de este módulo, una explicación de algunos de los elementos clave de un transformador puede ayudarle a entender cómo admiten la IA generativa.
Tokenización
El primer paso para entrenar un modelo de transformador es descomponer el texto de entrenamiento en tokens, es decir, identificar cada valor de texto único. En aras de la simplicidad, se puede considerar que cada palabra distinta del texto de entrenamiento es un token (aunque, en realidad, se pueden generar tokens para palabras parciales o combinaciones de palabras y signos de puntuación).
Por ejemplo, considere la siguiente oración:
I heard a dog bark loudly at a cat
Para tokenizar este texto, puede identificar cada palabra discreta y asignarle identificadores de token. Por ejemplo:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
La oración ahora se puede representar con los tokens: {1 2 3 4 5 6 7 3 8}. Del mismo modo, la oración "He oído a un gato" se podría representar como {1 2 3 8}.
A medida que continúa entrenando el modelo, cada nuevo token del texto de entrenamiento se agrega al vocabulario con los identificadores de token adecuados:
- meow (9)
- skateboard (10)
- y así sucesivamente...
Con un conjunto de texto de entrenamiento lo suficientemente grande, se podría compilar un vocabulario de muchos miles de tokens.
Inserciones
Aunque puede ser conveniente representar los tokens como identificadores simples (básicamente se crea un índice para todas las palabras del vocabulario), no nos dicen nada sobre el significado de las palabras o las relaciones entre ellas. Para crear un vocabulario que encapsule las relaciones semánticas entre los tokens, definimos para ellos vectores contextuales, conocidos como inserciones. Los vectores son representaciones numéricas de información con varios valores, por ejemplo [10, 3, 1] en las que cada elemento numérico representa un atributo determinado de la información. En los tokens de lenguaje, cada elemento del vector de un token representa algún atributo semántico de este. Las categorías específicas de los elementos de los vectores de un modelo de lenguaje se determinan durante el entrenamiento en función de cómo se usan las palabras normalmente juntas o en contextos similares.
Los vectores representan líneas en el espacio multidimensional al describir la dirección y la distancia a lo largo de varios ejes (puedes impresionar a tus amigos matemáticos llamándolos amplitud y magnitud). Puede ser útil pensar que los elementos de un vector de incrustación de un token representan pasos a lo largo de una ruta en un espacio multidimensional. Por ejemplo, un vector con tres elementos representa una ruta en un espacio tridimensional en el que los valores de los elementos indican las unidades recorridas adelante/atrás, izquierda/derecha y arriba/abajo. En general, el vector describe la dirección y la distancia de la ruta de acceso desde el origen hasta el final.
Los elementos de los tokens del espacio de inserciones representan algunos atributos semánticos del token, de modo que los tokens semánticamente similares deben dar lugar a vectores con una orientación similar; es decir, otras palabras que apuntan en la misma dirección. Se usa una técnica denominada similitud de coseno para determinar si dos vectores tienen direcciones similares (independientemente de la distancia) y, por tanto, representan palabras vinculadas semánticamente. Por ejemplo, supongamos que las inserciones de nuestros tokens constan de vectores con tres elementos, por ejemplo:
- 4 ("dog"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("cachorro"): [5,2,1]
- 10 ("monopatín"): [-3,3,2]
Estos vectores se pueden representar en el espacio tridimensional, de la siguiente manera:
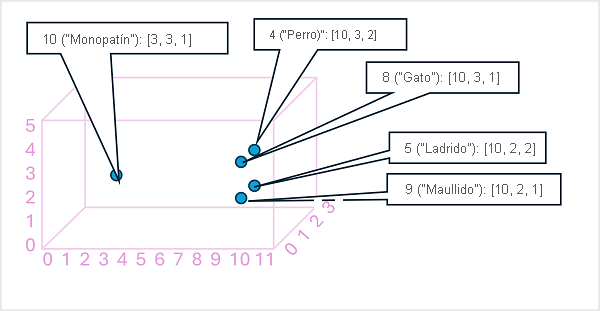
Los vectores de inserción para "perro" y "cachorro" describen un recorrido por una dirección casi idéntica, que también es bastante similar a la de "gato". El vector de incrustación de "skateboard" sin embargo describe el recorrido en una dirección muy diferente.
Nota:
En el ejemplo anterior se muestra un modelo de ejemplo sencillo en el que cada inserción tiene solo tres dimensiones. Los modelos de lenguaje real tienen muchas más dimensiones.
Hay varias maneras de calcular las inserciones adecuadas para un conjunto determinado de tokens, incluidos algoritmos de modelado de lenguaje como Word2Vec o el bloque codificador en un modelo de transformador.
Atención
Los bloques codificador y descodificador en un modelo de transformador incluyen varias capas que forman la red neuronal del modelo. No es necesario entrar en los detalles de todas estas capas, pero resulta útil tener en cuenta uno de los tipos de capas que se usa en ambos bloques: las capas de atención. La atención es una técnica que se usa para examinar una secuencia de tokens de texto e intentar cuantificar la fuerza de las relaciones entre ellos. En concreto, la autoatención implica considerar cómo otros tokens alrededor de un token determinado influyen en el significado del token.
En un bloque codificador, cada token se examina con atención en contexto y se determina una codificación adecuada para su inserción vectorial. Los valores vectoriales se basan en la relación entre el token y otros tokens con los que aparece con frecuencia. Este enfoque contextualizado significa que la misma palabra podría tener varias inserciones en función del contexto en el que se usa; por ejemplo, "the bark of a tree" significa algo diferente a "I heard a dog bark".
En un bloque descodificador, las capas de atención se usan para predecir el siguiente token de una secuencia. Para cada token generado, el modelo tiene una capa de atención que tiene en cuenta la secuencia de tokens hasta ese momento. El modelo tiene en cuenta cuáles de los tokens son los más influyentes al considerar cuál debe ser el siguiente token. Por ejemplo, en la secuencia "I heard a dog", la capa de atención podría asignar mayor peso a los tokens "heard" y "dog" al considerar la siguiente palabra de la secuencia:
I heard a dog [bark]
Recuerde que la capa de atención está trabajando con representaciones vectoriales numéricas de los tokens, no con el texto real. En un descodificador, el proceso comienza con una secuencia de inserciones de tokens que representan el texto que se va a completar. Lo primero que sucede es que otra capa de codificación posicional agrega un valor a cada inserción para indicar su posición en la secuencia:
- [1,5,6,2] (I)
- [2,9,3,1] (heard)
- [3,1,1,2] (a)
- [4,10,3,2] (dog)
Durante el entrenamiento, el objetivo es predecir el vector del token final de la secuencia en función de los tokens anteriores. La capa de atención asigna un peso numérico a cada token de la secuencia hasta el momento. Ese valor lo usa para realizar un cálculo sobre los vectores ponderados, que produce una puntuación de atención que puede utilizarse para calcular un posible vector para el siguiente token. En la práctica, una técnica denominada atención multicabezal usa diferentes elementos de las inserciones para calcular varias puntuaciones de atención. A continuación, se usa una red neuronal para evaluar todos los tokens posibles para determinar el token más probable con el que continuar la secuencia. El proceso continúa de forma iterativa para cada token de la secuencia, y la secuencia de salida se usa de forma regresiva como entrada para la siguiente iteración, es decir, se construye la salida token a token.
La siguiente animación muestra una representación muy simplificada de cómo funciona este proceso; en realidad, los cálculos realizados por la capa de atención son más complejos, pero los principios se pueden simplificar de la siguiente forma:

- Una secuencia de inserciones de tokens se introduce en la capa de atención. Cada token se representa como un vector de valores numéricos.
- El objetivo de un descodificador es predecir el siguiente token de la secuencia, que también será un vector que se alinea con una inserción en el vocabulario del modelo.
- La capa de atención evalúa la secuencia hasta el momento y asigna pesos a cada token para representar su influencia relativa en el siguiente token.
- Los pesos se pueden usar para calcular un nuevo vector para el siguiente token con una puntuación de atención. La atención multicabezal emplea diferentes elementos de las inserciones para calcular varios tokens alternativos.
- Una red neuronal totalmente conectada usa las puntuaciones de los vectores calculados para predecir el token más probable de todo el vocabulario.
- La salida prevista se anexa a la secuencia hasta el momento, que se usa como entrada para la siguiente iteración.
Durante el entrenamiento, se conoce la secuencia real de los tokens: solo se enmascaran los que aparecen más tarde en la secuencia que la posición del token que se está considerando en ese momento. Como en cualquier red neuronal, el valor previsto para el vector de token se compara con el valor real del siguiente vector de la secuencia y se calcula la pérdida. Los pesos se ajustan entonces incrementalmente para reducir la pérdida y mejorar el modelo. Cuando se usa para la inferencia (predecir una nueva secuencia de tokens), la capa de atención entrenada aplica pesos que predicen el token más probable en el vocabulario del modelo que está semánticamente alineado con la secuencia hasta el momento.
Todo esto significa que los modelos de transformador, como GPT-4 (el modelo que hay detrás de ChatGPT y Bing) están diseñado para tomar una entrada de texto (llamada mensaje) y generar una salida sintácticamente correcta (llamada finalización). En efecto, la "magia" del modelo es que tiene la capacidad de encadenar una oración coherente. Esta habilidad no implica ningún "conocimiento" o "inteligencia" por parte del modelo; solo un amplio vocabulario y la capacidad de generar secuencias de palabras significativas. Sin embargo, lo que hace que un modelo de lenguaje grande como GPT-4 sea tan eficaz, es el gran volumen de datos con los que se ha entrenado (datos públicos y con licencia de Internet) y la complejidad de la red. Como consecuencia de ello, el modelo es capaz de generar finalizaciones basadas en las relaciones entre palabras del vocabulario con el que se ha entrenado, y a menudo genera una salida que no se puede distinguir de una respuesta humana al mismo mensaje.